2025 AI Research Reflections
At NeurIPS this December, one moment has stayed with me more than any other: Kaiming He’s Test of Time Award talk. Watching him trace the arc of computer vision over the past two decades, I realized we weren’t just witnessing a history lesson—we were seeing a blueprint for understanding AI’s entire trajectory.
I. The Long Arc of Letting Go
The story Kaiming told is, at its core, about humans gradually stepping back and letting data find its own “best representation.”
- Hand-crafted Features (SIFT/HOG): In the beginning, humans told machines what to see. We manually defined features—edges, corners, gradients—essentially dictating the vocabulary of visual understanding.
- Hand-crafted Architectures (CNN/ResNet): The next leap was subtler but profound. We stopped designing features, but we still designed the inductive biases—the translation invariance of convolutions, the hierarchical structure of deep networks. We told machines not what to see, but how to look.
- Scalable Architectures & Objectives (Transformer/MAE/GPT): Now, we’ve retreated even further. We design minimal structures (the Transformer) and universal objectives (next token prediction, masked reconstruction), then step aside. Understanding emerges from scale and data, not from our careful engineering.
This pattern reveals something fundamental: the most impactful research tends to answer a single question—how can we trade less human constraint for stronger generalization?
II. The Great Reunification
This connects to something Shunyu Yao emphasized in “The Second Half”—the notion of utility as the North Star. Here’s a historical irony worth contemplating: the earliest AI researchers had grand, unified ambitions. They wanted to build systems that could interact with the world in all its complexity. But the problem proved too hard, so the field fragmented. Computer vision went one way, NLP another, robotics yet another. Divide and conquer became the survival strategy.
天下事,分久必合,合久必分—as the Chinese saying goes, “what is divided must eventually unite, what is united must eventually divide.”
2025 feels like a reunification point. The agent paradigm isn’t just a new research direction—it’s the field remembering its original ambition. And this work carries enormous value precisely because it continues the pattern: using less human constraint (separate pipelines for vision, language, planning) to achieve stronger generalization (unified systems that perceive, reason, and act). So what comes next? Perhaps we should be asking: How do we take these powerfully general agents and deploy them toward real-world utility? This isn’t just an industry concern—it’s where some of the richest scientific questions now live.
III. Three Directions I Want to Go Deeper On
Everyone’s research taste differs. Here are three areas where I find myself wanting to invest more time:
1. Agents Must Act
Memory and reasoning/planning are obviously critical, and researchers are flooding into those areas. My interest in function calling and tool use stems from a simpler observation: LLMs can only interact passively. Tools are what enable active engagement with the environment. Tools are also where the real reward signals live. When an agent calls an API and something happens in the world—a file gets created, a database gets queried, an email gets sent—that’s ground truth feedback. No human labeling required. Yet tool use remains surprisingly brittle, especially across multi-turn dialogues. As reasoning and memory capabilities improve, I suspect tool interaction will become the bottleneck constraining agent capability. The agent might “know” what to do and “remember” the context, but still fumble the execution.
2. Agents Must Collaborate
Once general-purpose agents are deployed at scale, they won’t exist in isolation. They’ll form groups, cohorts, even populations. We’ll need to think about multi-agent civilization, not just individual agent intelligence. Complex real-world tasks require collaboration. How do we ensure that different agents stay in their lanes while communicating efficiently? How do we prevent “profile collapse” where agents converge to homogeneous behavior? How do we control costs when orchestrating swarms of capable (and expensive) models? These aren’t distant concerns—they’re becoming urgent engineering and scientific problems for anyone deploying agents in production.
3. Agents Must Be Judged
Here’s a reversal that doesn’t get enough attention: in traditional ML research, the hard part was structural and methodological innovation. Evaluation was comparatively straightforward—you had benchmarks, you measured accuracy, you moved on. Now? Generation is the solved problem. Evaluation is the bottleneck. LLMs can produce hundreds of pages of content on demand. But how do we assess, compare, and judge the quality of that content? How do we know if one agent’s reasoning is actually better than another’s? How do we detect subtle failures in multi-step plans? Exploring the boundaries of evaluation is, in a sense, defining what intelligence is. And comprehensive, fine-grained evaluation is the only way to ensure that agents achieve their maximum utility. Without it, we’re flying blind.
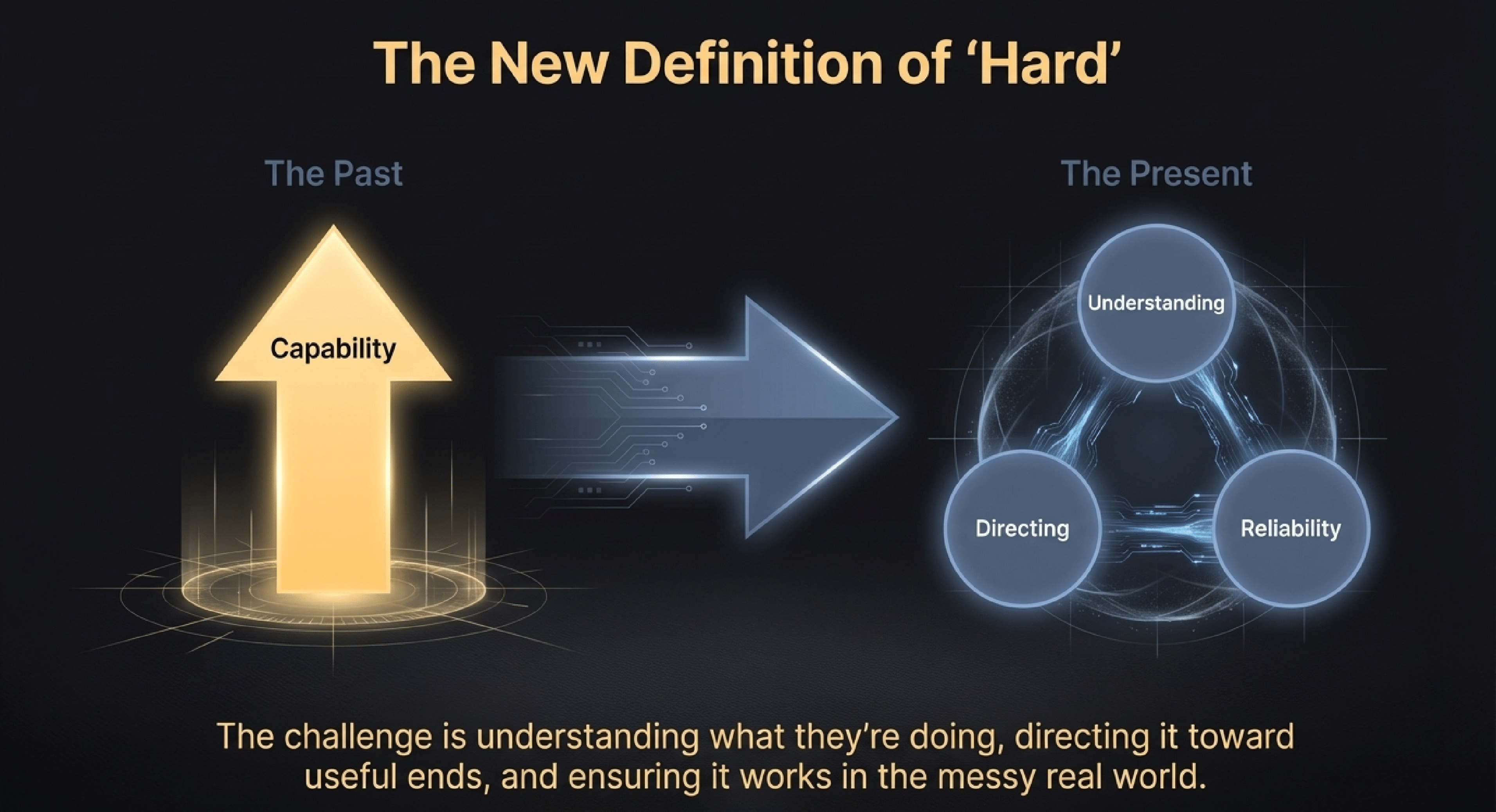
The thread connecting all of this is a shift in what “hard” means. For decades, the challenge was getting AI systems to do anything at all. Now the challenge is understanding what they’re doing, directing it toward useful ends, and ensuring it works reliably in the messy real world.
The researchers who thrive in this era won’t just be the ones who can train bigger models. They’ll be the ones who can answer: What does it mean for an agent to succeed? How do we measure it? And how do we build systems robust enough to deliver on that measure, again and again? Or, in short, Generalization towards Utility.
IV. The Vibe Coding Era
Vibe coding has rewritten the “Hello World” ritual. Anyone can now ship products in languages they’ve never learned. The market value of coding-as-craft is declining—and the speed of AI improvement makes me doubt the gap will last long.
But humans have never survived by being the best at everything. We adapt. We co-evolve. We did it with steam, electricity, and now AI. The question isn’t whether vibe coding replaces traditional programming—it’s what new value emerges.

Two things stand out:
Verification. Vibe coders steer, they don’t row. They can’t debug subtle flaws themselves. We need new infrastructure: AI code reviewers, automated test generators, systems that explain why code works or fails. The meta-skill shifts from implementing to verifying.
Taste. Vibe coding is the ultimate executor, but execution without vision is noise. The ability to connect ideas, spark innovation, and exercise aesthetic judgment remains human. Knowing which of ten correct solutions feels right, which interface delights, which architecture ages well.
This is what sets the ceiling. The bottleneck has shifted from “can you build it?” to “should you build it, and is it good?”