Mechanism
Why the test is diagnostic
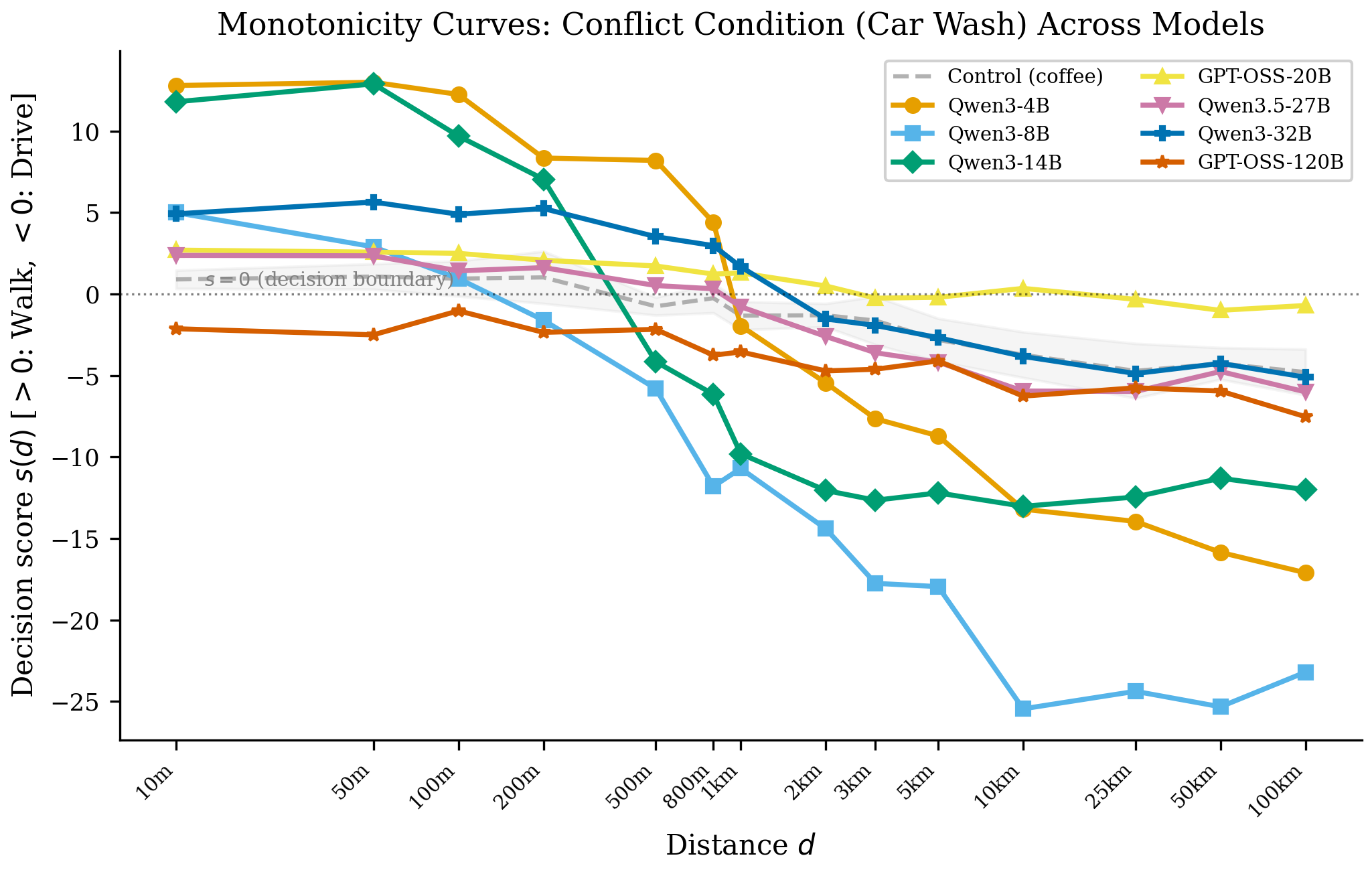
The input decomposes into three spans that pull the model in opposite directions. Across six open models, the distance span dominates the decision by 9–38×.
The structure
- goal “get my car washed” — implies the car must be co-located with the wash.
- heuristic “50 m away” — short distance ⇒ walking is the default answer.
- options walk vs. drive — a forced binary.
The correct answer is drive: you cannot wash a car that is not at the car wash. Yet every paraphrase, across every model we tested in Study 1, produces the wrong answer — 0% accuracy.