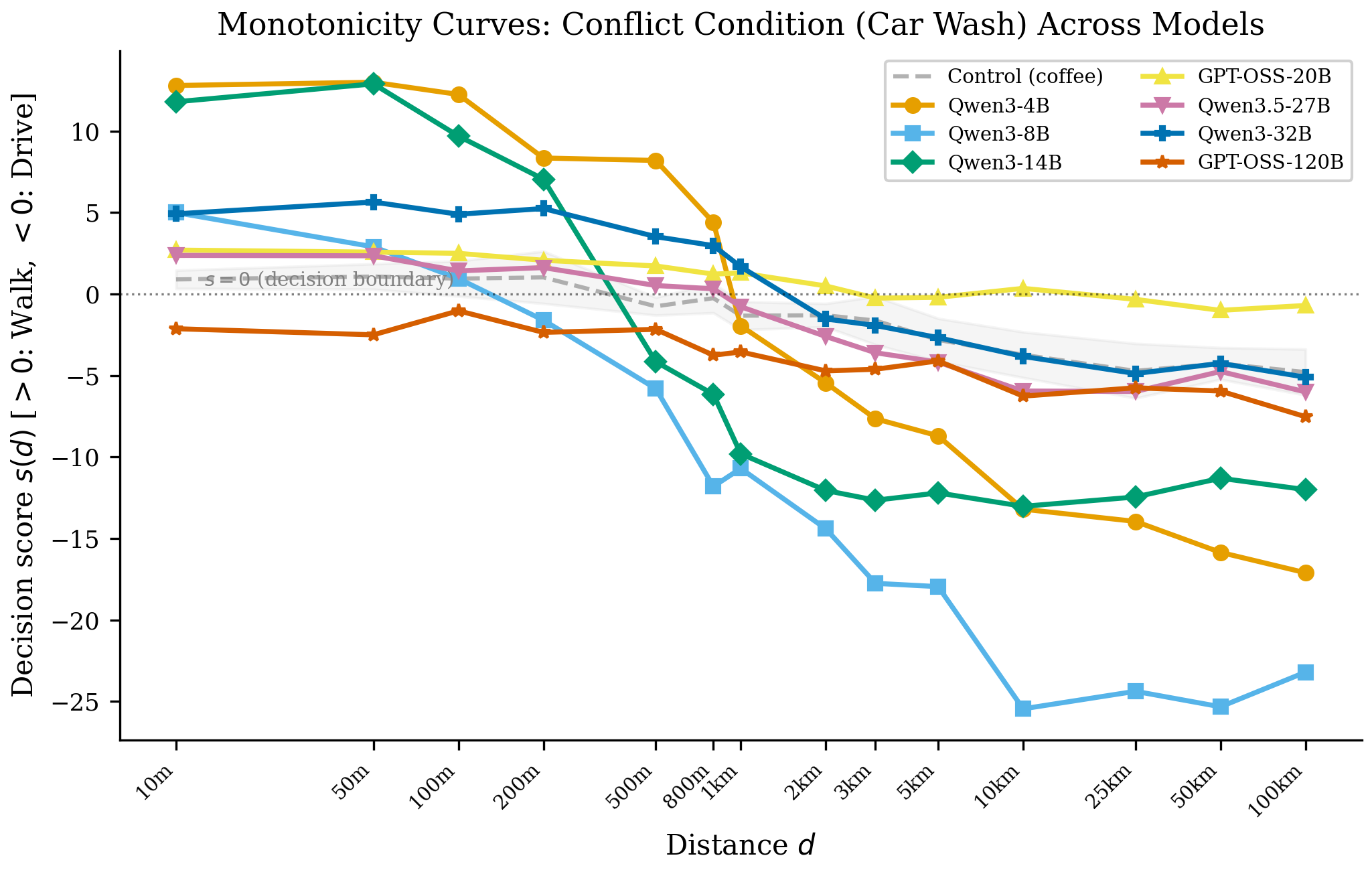
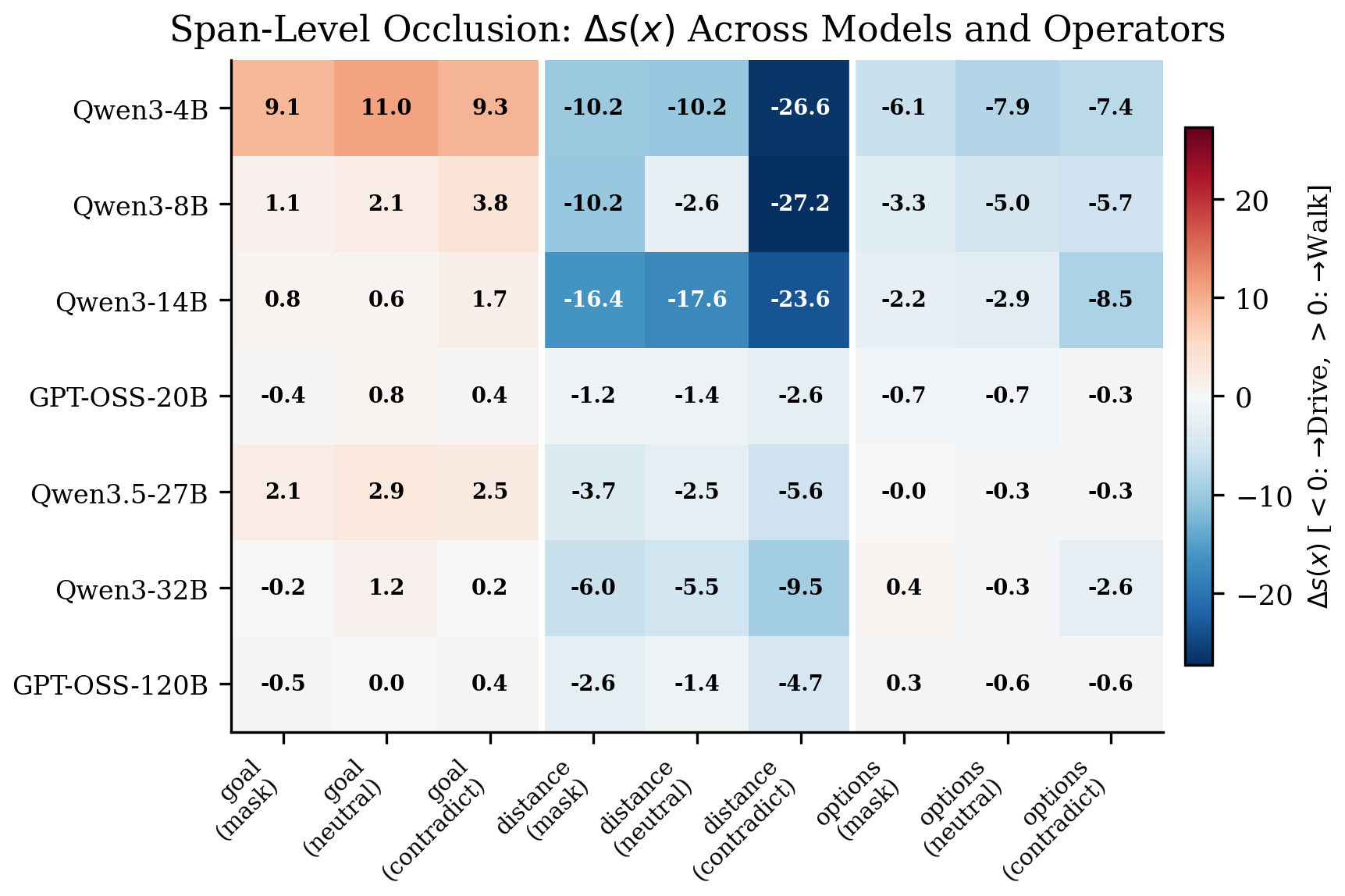
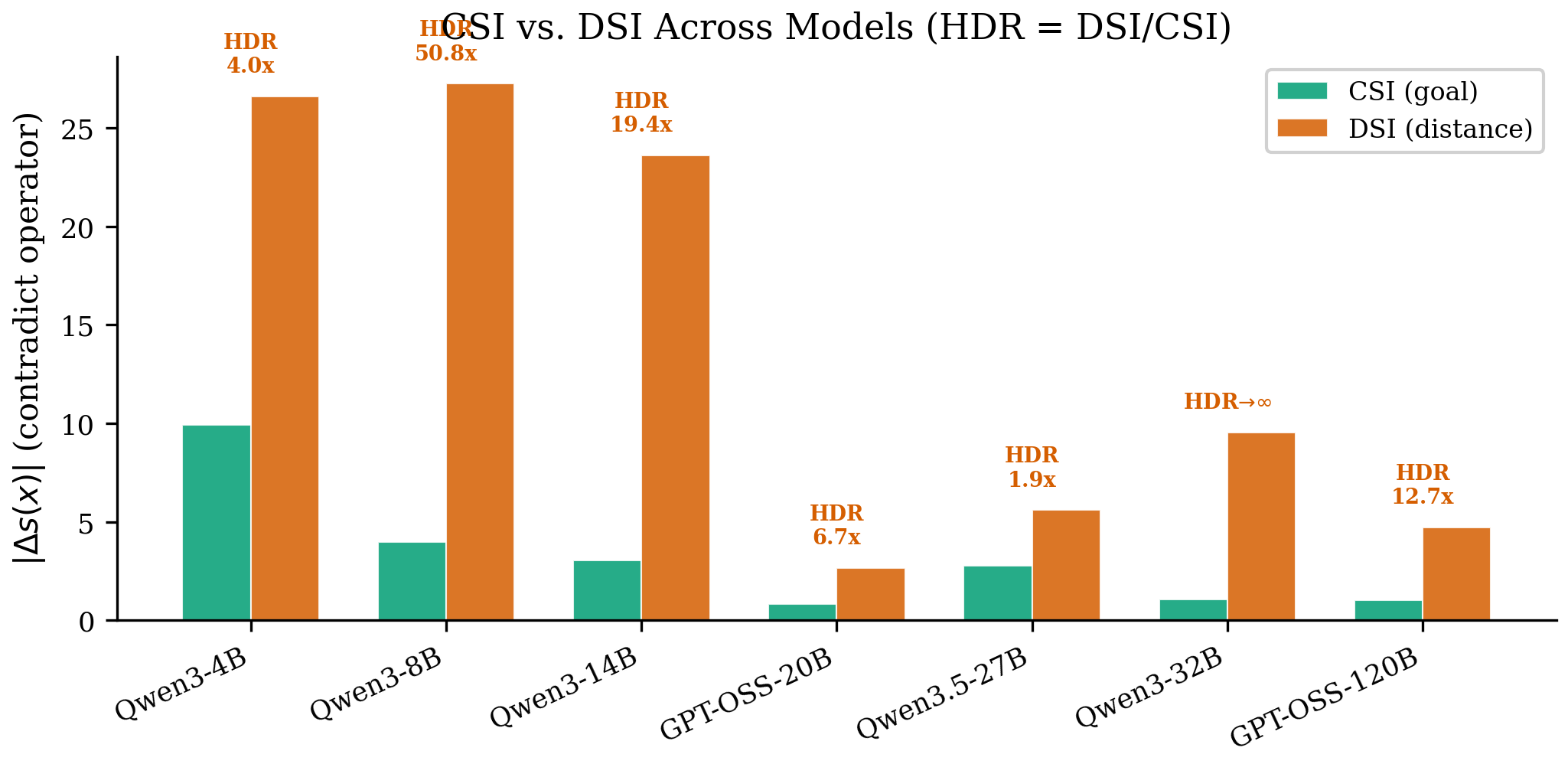
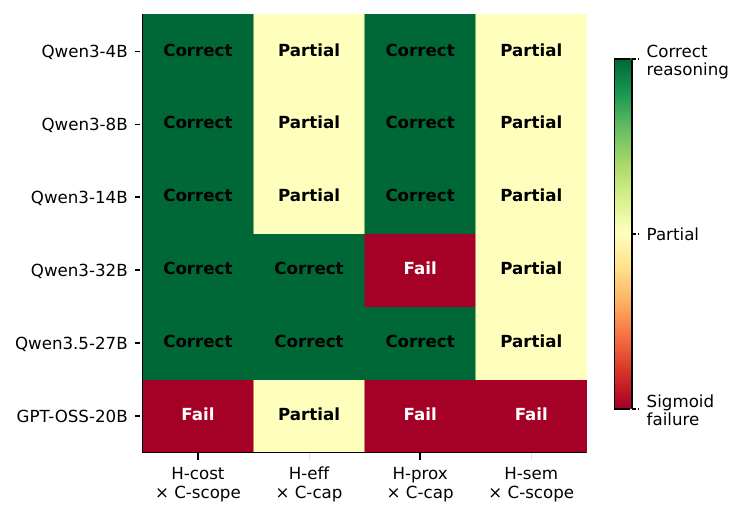
Where do models fail?
Mean strict accuracy by family
Across 14 models, C-pres (presence) is universally the hardest constraint family, directly validating the car-wash mechanism at scale. Cost-based heuristics (H-cost) are the easiest to override; proximity (H-prox) and semantic (H-sem) cues are the hardest.
By constraint family
Mean ± range across 14 models. C-pres (44.4%) is hardest; C-cap (71.6%) is easiest.
By heuristic family
Cost cues are easiest to override; proximity and semantic-match cues the hardest.
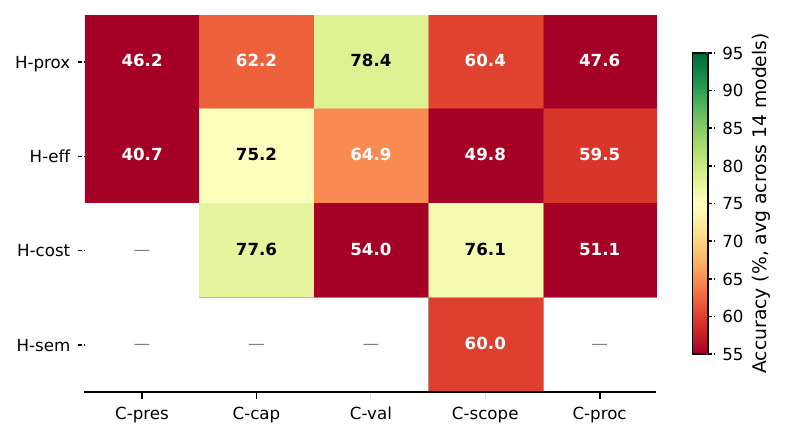
H × C cell heatmap (14-model mean)
Cells A1 (H-prox × C-pres) and B1 (H-eff × C-pres) are the hardest; several models fall below 30% on these cells.