Overview
Across the six application domains (training, inference, routing, RAG, risk, agentic), five systemic challenges recur. These are not bugs in individual papers, but rather fundamental tensions that limit the maturity of confidence-guided control.
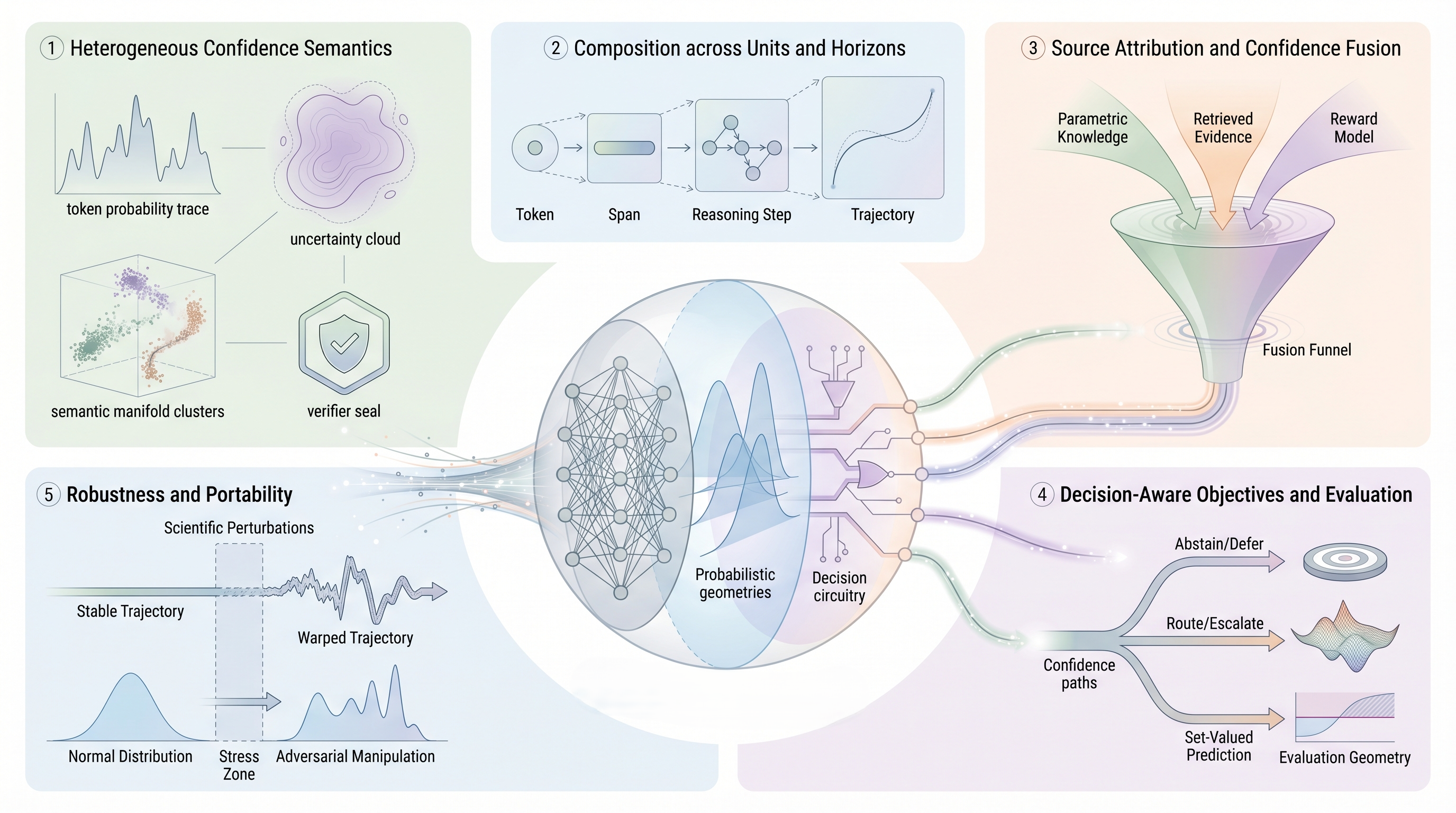
Challenge 1: Heterogeneous Confidence Semantics
Verbalized confidence ("I am 90% sure"), agreement (answer frequency across samples), semantic entropy (entropy over semantic clusters), process reward model scores, and peer confidence from multi-agent voting are all useful. But are they measuring the same thing?
The problem: These signals can correlate negatively. A sample with high semantic entropy (disagreement) may still have high verbal confidence ("The answer is X, and I'm sure"). A process reward may score a step highly even though the next step is uncertain. A large-scale verifier may disagree with a small-scale self-check.
Current practice: Most methods pick one source and stick with it (SELF-RAG uses reflection tokens; LATS uses value + reflection; ReConcile uses peer voting). When systems combine sources (CRAG, UP-RLHF), they typically average or ensemble without preserving which signal is which.
Path forward: Develop semantically grounded confidence representations. Rather than treating confidence as a scalar, represent it as a structured belief: "I am 90% confident in X under assumptions A, B, C." This enables transparent comparison and composition. Mechanistic interpretability (probing, causal intervention) may help ground these signals in model behavior.
Challenge 2: Composition Across Units and Horizons
Individual units (tokens, claims, steps) have confidence scores. But how do these compose to trajectory-level confidence?
The problem: A trajectory with five high-confidence steps can still fail if the steps are dependent and one mistake cascades. Conversely, a trajectory with one low-confidence step may succeed if that step is independent. Token-level confidence does not directly predict answer-level confidence. Claim-level confidence does not predict full-response grounding.
Current practice: Methods use heuristics: minimum confidence (most conservative), average or product (geometric mean), or train auxiliary models (process rewards, trajectory rewards) to predict global confidence. But these are not principled; different problems likely require different composition rules.
Path forward: Study composition rules empirically and theoretically. Under what conditions is confidence subadditive (worse than product) or superadditive (better)? Learn composition functions end-to-end alongside base confidence models. Develop formal methods (e.g., probabilistic graphical models) that respect dependencies and causal structure.
Challenge 3: Source Attribution and Confidence Fusion
Best systems combine multiple sources: self-confidence, auxiliary verifiers, external retrievals, peer votes. But tracking provenance and preventing unjustified fusion is hard.
The problem: When a verifier model is trained on biased data, its confidence can propagate to downstream decisions. When self-confidence is "hijacked" by prompt injection, it can override sound auxiliary signals. When confidence from multiple sources is naively averaged, their individual calibration is lost. We lose the ability to ask: "Why did the system make this decision?" and "Which signal was responsible?"
Current practice: Most systems either use a single source (limiting expressivity) or fuse sources via learned weights without interpretation. ReConcile and ConfMAD aggregate agent votes, but don't track source provenance.
Path forward: Develop confidence aggregation methods that preserve attribution. Use techniques from Shapley values or SHAP to quantify each source's contribution to final decisions. Tag confidence signals by source (self, auxiliary model, retrieval, peer) and make the attribution explicit in logs and explanations. Enable rollback: if one source is corrupted, decisions remain valid conditioned on removing that source.
Challenge 4: Decision-Aware Objectives and Evaluation
Calibration (confidence matches true accuracy) is not the same as routing quality, conformal efficiency, or abstention quality. Yet many papers optimize for calibration and assume it transfers to downstream tasks.
The problem: A model can be perfectly calibrated but still bad at routing (its confidence may not correlate with answer quality). A routing system can have high efficiency (uses few queries to reach high accuracy) but poor coverage guarantees (sometimes fails silently). An abstention policy can be conservative (rarely wrong) but unusable (abstains on 80% of queries).
Current practice: Papers optimize for different metrics with little coordination: Calibration (ConfTuner), routing accuracy (RouteLLM, CARGO), conformal coverage (TRAQ, Conformal Factuality), abstention F1-score (R-Tuning). Results don't generalize across tasks or settings.
Path forward: Define task-specific confidence objectives. For routing, optimize for cost-accuracy tradeoff given a model portfolio. For RAG, optimize for retrieval quality weighted by context utility. For risk, optimize for selective reliability (high accuracy on answered queries, low error rate). Make the downstream decision explicit in the loss function and evaluation metric.
Challenge 5: Robustness and Portability
A confidence system trained on one model, prompt format, task distribution, or threat model often fails in another setting.
The problem: Self-confidence (token probabilities) is calibrated for closed-ended QA but breaks on reasoning tasks with multiple valid paths. Semantic entropy works for semantic agreement but fails when linguistic diversity is high. Process rewards trained on one domain don't generalize to another. Confidence signals degrade under distribution shift, adversarial prompts, or fine-tuning.
Current practice: Most papers evaluate on a fixed benchmark (MMLU, GSM8K, HotpotQA). Claims of "generalization" typically mean within-domain transfer. Robustness to OOD data, adversarial examples, or new model architectures is rarely tested.
Path forward: Design confidence systems with explicit robustness objectives. Test confidence signals under distribution shift (new tasks, domains, languages), prompt injection, fine-tuning, and model scaling. Develop meta-confidence signals that detect when base signals are unreliable. Curate open benchmarks that measure robustness across diverse settings. Study the stability of confidence under model updates and continual learning.
Conclusion: The Path Forward
Confidence is most powerful as a control signal. The next generation of systems will need to address these five challenges systematically:
- Semantically interpretable — confidence representations that preserve meaning and enable transparent comparison.
- Composable — principled methods to combine unit-level and trajectory-level confidence with formal properties.
- Source-aware — systems that track provenance, enable attribution, and support rollback on corrupted signals.
- Decision-aware — objectives indexed to downstream actions (routing, selection, abstention, escalation).
- Robust — confidence signals that remain reliable across model families, domains, prompt formats, and threat models.
This survey has catalogued the current landscape: 200+ papers across six domains, using confidence to shape training data, direct inference, route models, gate retrieval, detect hallucinations, and guide agentic search. The depth and breadth of work is impressive. The challenges ahead demand equal rigor.